
|
There are isolated problems with current patches, but they are well-known and documented on this site. |
In this issue PUBLIC DEFENDER: Browsers with the best security and privacy in 2021 LEGAL BRIEF: The best things in life are copyrighted LEGAL BRIEF: The problem with copyright: fair use LEGAL BRIEF: Dickens was right (for the wrong reason)
FROM THE EDITOR SPECIAL EDITION: Cyber Monday!
By Will Fastie Our writers have the week off. No rest for the editor, though. We decided to publish an issue for you anyway. In today’s special edition, we feature a brand-new article from Brian Livingston about browser security. And we’re bringing you three of Max Oppenheimer’s most popular columns about copyright law, which puts them all in one convenient place. These three articles have not previously been available to free-edition subscribers. Unlike most issues of the free edition, this one contains all four articles, in full, not teasers. We wanted you to see the kind of work we’re doing and plan to continue over the coming months and years. This week, you are seeing exactly what our Plus members are seeing. Why? Because we want you to become an AskWoody Plus Member with a small donation. If just one tip you pick up in one article in the newsletter saves you hours of time and frustration, isn’t that worth a couple of bucks per month? We hope you’ll agree, and we hope you’ll like this special edition of the AskWoody Free Newsletter. Tell your friends! And best wishes for the holiday season.
PUBLIC DEFENDER Browsers with the best security and privacy in 2021
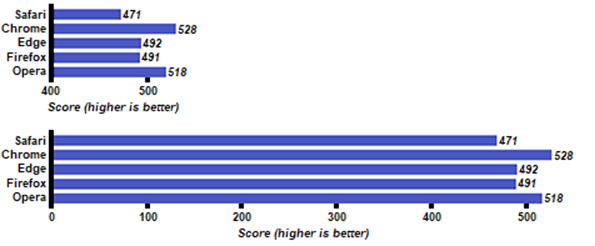
By Brian Livingston Most of us use a Web browser on our personal computers or smartphones every day, but few of us truly know what those browsers are really doing for us — or to us. Too many browsers are vulnerable to malware or “leak” information about us and our everyday activities to backend servers, which are run by ad-tracking firms, search-engine giants, or the browser makers themselves. It’s extremely difficult to guess which browser is the “most secure” for surfing the Web. There are, to be sure, many respectable review sites that rank browsers. But most of the reviews weigh a browser’s security against unrelated features — ease of use, speed of throughput, memory usage, etc. — producing only a composite score. In this article, I focus solely on how well browsers deliver security against malware and protect the privacy of your personal identity. Reviewing only those two criteria won’t make everyone happy. But in case you just want to know about rendering speed, one PC review site showed that, of the five most popular browsers, Chrome’s rendering of an HTML5 test was 10.8% faster than Safari’s (an insignificant difference, as shown in Figure 1). The review also tested seven “alternative browsers,” some of which provide much better security and privacy than the big names, and then ranked the seven — in alphabetical order. Thanks for the guidance!
Browser security isn’t just a button you press
One of the best critiques of browser security has been posted online by a developer who goes by madaidans. As a security researcher and contributor to Whonix — an operating system that runs inside desktop OSes and then transmits data through The Onion Router (i.e., the Tor anonymizing network) — madaidans has formed some very definite opinions. The blog mercilessly flogs improvements for such pillars of virtue as Android, Firefox, Linux, and Chromium — the base code underlying numerous browsers including Brave, Google Chrome, Epic, Opera, Vivaldi, and, since January 2020, Microsoft Edge. There are enough good ideas in here to offend everyone. For example, “Firefox is sometimes recommended as a supposedly more secure browser because of its parent company’s privacy practices,” madaidans writes. “This article explains why this notion is not true.” Hey, don’t hold back! Say what you really think! This withering analysis — and takedowns of many other accidents waiting to happen — are all linked to from madaidans’s main security page at GitHub.io. Let this be a reminder to us that all sorts of software vulnerabilities still remain in well-known products. While we’re waiting for perfection, let’s survey the most recent browser ratings — purely from a security perspective — by other knowledgeable reviewers: ZDNet (a tech publisher) review: McAfee (the giant antivirus company) recommendations: ExpressVPN (a British Virgin Islands VPN provider with users in 180 countries) ranking: RestorePrivacy (a US-based site for security-oriented journalism) review: SafetyDetectives (a security consultancy based in the UK) review: Privacy Canada (a Toronto affiliate of EFF, the Electronic Frontier Foundation) review: You may notice a pattern here. Browsers from security-focused upstarts, such as Brave and Tor, enjoy high ratings. Apps from corporate giants bring up the rear. However, even if you scrutinized every rating in the world, no browser can ever be 100% malware-proof. For instance, you may or may not be saved from doom if you make the mistake of clicking within a genuine-looking email that says: “You need to change your password today.” As an example of a worst-case scenario, owners of iPhones were victimized by “zero-click” malware called Pegasus from May 2018 through July 2021. It reportedly infected 50,000 users worldwide — largely journalists and human-rights activists — without their even picking up their oh-so-smart phones. As described in a CNBC article, no matter what browser was installed, it was no help! In addition to caring about browser security, most tech reviewers recommend the use of an antivirus program for protection from malware and a VPN (virtual private network) for privacy. See AskWoody’s recent antivirus reviews and VPN articles. Leaks of data privacy are just as concerning as browser security
The fact is that advertising on the Internet is the tail wagging the dog. There’s lots of information on the Web, but what we see is skewed by advertisers’ desire to know as much about each of us as possible. Just to name one example at random, advertising produced 97.9% of the total global revenue of Facebook Inc. (now Meta Platforms Inc.) in 2020, according to Statista data. With the pressures the advertising industry places on browser magnates to report everything possible about us, digital privacy can’t be treated as an afterthought. Data security goes hand in glove with anti-malware security. Random people having access to your IP address, which can lead to your real-world identity, leaves you open to spear-phishing tricks, ransomware attacks, and other badness. Do you really want strangers knowing that you visited websites about sexually transmitted diseases? (You probably have other examples, which are limited only by a hacker’s fevered imagination.) Privacy is now being threatened by a relatively new technique called Canvas fingerprinting. As a well-intentioned feature of HTML5 — which most browsers have gradually embraced from 2014 on — Canvas was introduced to help websites draw images on-screen. About 6% of the Internet’s top websites currently track visitors via Canvas fingerprinting, according to a scan that tech newsroom The Markup describes. The problem arises because practically every device renders a Canvas image in a slightly different way. This is due to the almost infinite variations of browsers, software algorithms, installed fonts, video drivers, and other factors. As a result, about 99.83% of Web users have a Canvas signature that’s unique. That makes this snippet of binary data — a hash value that’s only a few bytes long — ideal for user tracking. (BrowserLeaks, a diagnostic website, reports that only 1,488 of more than 850,000 of its visitors possessed identical signatures. All the other devices had unique sigs, according to BrowserLeaks’ testing page.) Various browser add-ons — and the Brave, Firefox, and Tor browsers themselves — block Canvas fingerprinting by default or by making optional settings available. (To enable blocking in each product, see RestorePrivacy’s how-to page). Other browsers may or may not defend against Canvas fingerprinting. Try the following:
Other privacy leaks aren’t blocked by browsers, either
A ray of sunshine was beamed into the secretive world of browsers — and how they feed data about you to backend servers — with the publication of “Web Browser Privacy,” a massive exposé in the May 2021 issue of IEEE Access, a technical journal. Led by Douglas Leith of Dublin’s Trinity College, the researchers corralled several significant browsers, decrypted their traffic, and analyzed every byte that was sent to an astonishing array of ad trackers, consumer databases, and more.
To monitor each browser’s leaks to backend servers, the study routed all Web traffic through the laptop using MITMProxy (Man-in-the-Middle Proxy). This software is free and open source, so Leith’s browser tests can be repeated by anyone who wishes to use their own setup. (The code is available from mitmproxy.org.) The IEEE white paper is more than just another quibble about browser security:
The study clears up a few misconceptions about browser security. For example, the paper approves of the “safe browsing services” that nearly all major browsers use to warn users against visiting hacked websites. Today’s browsers maintain a list of malicious sites locally. The user’s copy is hashed, making it unreadable to the human eye but able to check URLs without contacting a browser’s sponsor. “In this way,” the white paper explains, “browser URLs are never sent in full [from users’ devices] to the safe browsing service.” The study reveals, however, that browsers send to backend servers other user information that’s more horrifying: Overall, we find that both the desktop and mobile versions of Brave do not use any identifiers allowing tracking of IP address over time, and do not share details of web pages visited with backend servers. In contrast, Chrome, Firefox, Safari and Edge all share details of web pages visited with backend servers. Additionally, Chrome, Firefox and Edge all share long-lived identifiers that can be used to link connections together and so potentially allow tracking over time. In the case of Edge these are device and hardware identifiers that are hard/impossible for users to change. The author reports that “Edge makes connections to a number of Microsoft administered domains … as well as to the ad tracking domain scorecardresearch.com.” That website states: “ScorecardResearch collects data that assists companies around the world in providing products and services.” I’ll bet it does! In a November 17, 2021, blog post, security expert Bruce Schneier adds fuel to the fire (in comments unrelated to the white paper): “Edge urges users to store passwords, ID numbers, and even passport numbers, all of which get uploaded to Microsoft by default when synch is enabled.” We’ve seen this movie before. Some browsers are good on user privacy, while others allow holes in your safety net. Figure 2 shows the leaks the researchers observed during startup, surfing, or restart of each browser. The rows are sorted in roughly the order of those browser families with the fewest data leaks to those with the greatest number of leaks. In Figure 2, the rows are sorted in roughly the order of those browser families with the fewest data leaks to those with the greatest number of leaks. For example, the Brave browser leaks the fewest details to backend servers.
Leith’s full white paper, with a free PDF download, is available at an IEEE abstract page. What’s the bottom line after all this? Be brave, my fellow sufferers.
It’s almost overwhelming to catalog the number of browser problems that ordinary computer users are expected to deal with. Most people, after all, have families to feed and jobs to do besides installing security fixes all the time to avoid their devices’ being slimed by phishing or worse. Considering all the above research, I know what the answer will be for the dozen-odd devices, large and small, that quietly hum throughout my office and in my pockets. They’re all getting a fresh install of the Brave browser. (As a competitor, Tor — no pun intended — is super private, but its VPN is widely reported to materially slow Web surfing.) Brave’s CEO, Brendan Eich, devised JavaScript in 1995 and co-founded the Mozilla project in 1998 that produced Firefox. I’d say this qualifies him to create a compelling new browser for today’s Roaring Twenties. I’ll probably set off a flame war by saying this: Everyone doesn’t have to use the same browser. Your preferences and needs may be very different from mine. To each their own! Good luck in whatever ways you decide to protect yourself.
The PUBLIC DEFENDER column is Brian Livingston’s campaign to give you consumer protection from tech. If it’s irritating you, and it has an “on” switch, he’ll take the case! Brian is a successful dot-com entrepreneur, author or co-author of 11 Windows Secrets books, and author of the new book Muscular Portfolios. Get his free monthly newsletter.
LEGAL BRIEF The best things in life are copyrighted
By Max Stul Oppenheimer, Esq. At least on the Web. Even though there is a sea of material there for almost effortless copying, nearly everything on the Internet is subject to copyright law. And the purpose of copyright law is specifically to protect the creators of copyrighted works from unauthorized copying. Here’s the problem that intellectual property law is designed to solve. Innovation is a gamble. It takes time, effort, and money to develop something new, and it is hard to predict whether the gamble will pay off or not. On the other hand, copying is far less expensive and far less risky. The original of Windows 10 probably cost a billion or so to produce; each additional copy probably costs about a dollar, including shipping and handling. Without intellectual property protection, a competitor could charge much less for the same product — they would not need to recover R&D costs. If competitors could do that, there would not be much incentive to be an innovator. Intellectual property is the legal tool for re-establishing a level playing field for innovators. Copyrights are but one type of intellectual property. There are several other types, each of which can create liability, but for now we’ll focus on copyrights. They protect artistic expression, which includes pictures, words, sounds — anything artistic that is fixed in a tangible medium (printed on paper, exposed on film, stored on a flash drive, etc.). A copyright owner can prevent others from copying, publicly displaying or performing, or preparing works that are based on the copyrighted work. These activities are referred to as copyright infringement and the owner can recover damages. Copyrights exist as soon as a work is fixed in a tangible medium, meaning if you can see it on the Internet, odds are it is copyrighted. And that means that forwarding it to a friend (copying), posting it on your own website (copying), or incorporating it into a work that you’ve created (copying, creating a derivative work) are all potentially infringing activity. But isn’t that what the internet is all about? Sharing? So why aren’t we all spending most of our time defending copyright-infringement suits? The most common answer is probably that the copyright owners don’t care. If you’d like to email a copy of this article to a friend, feel free! (I’d appreciate it if you gave me credit.) It’s here to share information and your dissemination helps. Not all copyright owners will feel that way. For example, Microsoft’s balance sheet shows nearly $60 billion in intangible assets and good will (i.e., copyrights, trademarks, patents) versus a mere $38 billion in tangible property and equipment. Microsoft is not about to let anyone take that away without a very expensive fight. And those copyright owners who do care have several tools at their disposal to express their caring. All major platforms provide a mechanism for takedown notices, allowing copyright owners to insist on removal of posts that contain copyrighted material. The rules apply not only to wholesale copying of entire works, but also to works that include copyrighted works as elements — posting a video of a dance to the tune of a copyrighted song is technically infringement of the copyright on the song (copying and public performance). In addition, the copyright owners can get an injunction requiring removal of the infringing work as well as damages for the infringement. Recognizing that damages can be difficult to prove, the copyright statute also provides for statutory damages, which the copyright owner can recover without proving actual damages. These range from $500 to $100,000. “Fair use” — the right to make limited use of limited portions of copyrighted works for specific purposes including criticism, comment, news reporting, teaching, and scholarship — is a concept built into the copyright statute. Fair use is not broad enough to cover all Internet uses. Note that incorporating someone else’s copyrighted work into your work is not fair use simply because you are not charging for your work. That may change, however, once the copyright “small claims court,” authorized last year, becomes reality. That tribunal is supposed to make it easy and cheap to file claims up to $30,000. The details are still at least a year away while the US Copyright Office sets up the program, but lowering the cost of enforcement will certainly enlarge the number of copyright owners willing to pursue infringers. So what can someone who wants to “use” something found on the Internet do to protect himself or herself? Unfortunately, not much. The guaranteed solution would be to obtain a license from the copyright owner — easier said than done. First, copyrights exist even if they are not registered with the Copyright Office. Even if they are registered, they can be searched for by only title and author — two data points that are unlikely to be obvious from simply seeing the work on the Internet — or by assignee, if the copyright has been assigned and the assignment has been registered. Thus the first indication of the owner’s identity might well be a cease-and-desist letter from the owner’s lawyer. Some works are openly dedicated to the public domain and do not require licensing (Linux, for example, which explains why there are so many proprietary versions available). But simply finding something on a website without a copyright notice, or even on a website stating it is public domain, is not a guarantee of safety. Copyrights belong to the creator of the work, so there are at least two situations where copying from a “public domain” website could still lead to trouble. For example, if the public-domain website copied the work without permission, or if the public-domain website had a license but its terms were not broad enough to permit further dissemination, the user would need to identify the owner of the copyright and ask to see the license document. Not likely. So how can you be absolutely safe? Do it yourself — use nothing but entirely original content. That will avoid copyright issues. Even so, remember that there may be other issues: patents, trademarks, trade secrets, boat hull designs…. The alternative is to accept the risk and hope you are not successful enough to attract attention — or successful enough to afford the litigation.
Max Stul Oppenheimer is a tenured full professor at the University of Baltimore School of Law, where he teaches Business and Intellectual Property Law. He is a registered patent attorney, licensed to practice law in Maryland and D.C. Any opinions expressed in this article are his and are not intended as legal advice.
LEGAL BRIEF The problem with copyright: fair use
By Max Stul Oppenheimer, Esq. All might be fair in love and war, but not in copyright If you think about copyrights for a moment, it might occur to you that they are unconstitutional. After all, the First Amendment says that Congress shall make no law abridging the freedom of speech. Yet there it is, in Title 17 of the U.S. Code: a law saying that Congress has given copyright owners the power to stop others from copying or publicly performing their copyrighted words. Copyright scholars see ways around this dilemma. First, they would observe, copyright controls only particular ways of expressing an idea, not the idea itself. That would still leave a problem: suppose you wanted to comment on someone’s copyrighted work – it might be difficult to do that if you couldn’t refer to the work. It might even be impossible: how could you comment on a politician’s speech if you couldn’t quote the words you were commenting on? A second concession to the First Amendment is the concept of “fair use.” Long before it was added to the Copyright Statute, courts considered that fair use implied that certain activities were excluded from the rights of copyright owners. An early case involved the publication of a two-volume biography of George Washington that used 353 pages from another author’s 12-volume biography. The judge — later-to-be Supreme Court Justice Joseph Story — observed: “A reviewer may fairly cite largely from the original work, if his design be really and truly to use the passages for the purposes of fair and reasonable criticism. On the other hand, … if he thus cites the most important parts of the work, with a view, not to criticize, but to supersede the use of the original work … such a use will be deemed in law a piracy.” This principle made it into the 1976 Copyright Act as Section 107 under the heading “fair use.” This is an unfortunate choice of words, suggesting that if it’s fair, it’s OK. So, for example, copying something you found on the Internet to your webpage certainly seems fair. After all, if something’s on the Internet for free, why shouldn’t you be able to copy it? Odds are it is not fair use, reasonable as the argument appears. The fair-use solution
Fair use is a technical term defined by Section 107 as the use of a copyrighted work “for purposes such as criticism, comment, news reporting, teaching (including multiple copies for classroom use), scholarship, or research … .” The statute goes on to provide four factors to be considered in determining whether a particular use is a “fair use:”
Thus, commercial uses are less likely to be fair use than are nonprofit uses; using a creative work is less likely to be fair use than using a factual work; using a little is more likely to be fair than using a lot; and uses which might compete with the original are less likely to be fair than those that do not. If that seems less than helpful, it is deliberately so. The legislative history regarding Section 107 states, “the endless variety of situations and combinations of circumstances that can rise in particular cases precludes the formulation of exact rules in the statute.” So copying something from the Internet for use on a website and relying on fair use is a risk. There is no bright-line test that assures you the use is permitted. Looks fair
We can, however, identify some uses that seem fair but aren’t. For example, since one of the factors is whether the use is commercial, it might be tempting to think that not charging for access to the particular work would make it a fair use. It probably won’t. First, a court would look not just at the price charged to access the work but at whether the website profited in any way from the copyrighted content it “borrowed.” That was the basis on which the court held that PublicResource.Org (defunct) had violated copyright by placing the Georgia Code on its website – it did not charge to access it, but it benefitted through contributions. Second, even if the borrower did not profit, a court might still conclude that the use was not fair because it cut into sales of the original, as it did when the Free Republic made Los Angeles Times articles available for free, whereas the Times held them behind a paywall. It might be tempting to think that using only a small component would certainly be safe. While “less is better,” courts look at more than math, and taking “the heart” of a work is not likely to be fair. In one case, a magazine published fewer than 400 words out of a total of 200,000 of President Ford’s memoir (that’s one-half of one percent). They happened to be the 400 words concerning the pardon of President Nixon, and the Court was persuaded that that was the part that many potential buyers of the memoir would be willing to pay for – thus not a fair use. Then what’s safe?
There’s nothing that you can be certain will prevent you from getting sued, but there are some activities that are safer than others.
“But how about what I really want to do … I want to use someone else’s work on my website.” Some of those uses may be OK if they are “transformative” — that is, they use the work for a different purpose than the original and don’t take away a sale by creating a competing version. There is a 9th Circuit decision holding it fair use for an image search engine to post thumbnails of entire art works, because they were not sufficiently high-resolution to substitute for the original and the purpose of the use was a good one. It isn’t a Supreme Court decision (it’s only one level down, but that’s a big step), and, as noted above, every case rests on its own facts. The case also illustrates the difference between a legal win and an economic win. The defendant lost in the trial court – meaning it spent a lot of money. The reversal by the Court of Appeals was good news for the defendant, but sending the case back to the trial court meant more money and risk; the defendant ran out of money before the case was resolved. The lawyers would count that as a win. (The same case suggests another option, which appears safer than copying: linking to the original website.) At the other end of the spectrum, if you have more money than you can spend, you might be able to digitize the world’s literature and convince a court that it is a “transformative fair use,” enabling textual analysis that is impossible with the original print edition. Google pulled it off (twice), at least in the lower courts. But then, they can afford the appeals.
Max Stul Oppenheimer is a tenured full professor at the University of Baltimore School of Law, where he teaches Business and Intellectual Property Law. He is a registered patent attorney, licensed to practice law in Maryland and D.C. Any opinions expressed in this article are his and are not intended as legal advice.
LEGAL BRIEF Dickens was right (for the wrong reason)
By Max Stul Oppenheimer, Esq. In Oliver Twist, Charles Dickens wrote, “The law is a ass …” He went on to say the law is also an idiot, but there we part company. The law is, in fact, an ass in the sense that it is slow to change and easily spooked by sudden moves. The problem with the legislature
In particular, by its nature, statutory law lags behind technological progress. The process of passing a law is time-consuming in itself, but it does not even begin until someone recognizes a problem that needs to be addressed. Once the problem is recognized, it must be defined in a way that legislators can understand, and a consensus must be reached as to how to address the problem. This can be a lengthy process. For example, in 1976 Congress recognized that copyright law as then written presented problems for computer software. At the time, software was provided on removable media which needed to be loaded into RAM in order to function. Technically, that meant that the software was copied — a violation of copyright. Congress created a commission to study how to address the problem and to recommend revisions to the Copyright Act. The commission issued its 350-page report in 1978, which Congress boiled down to roughly 400 words enacted in 1980 as Section 117 to the Copyright Act. Congress made clear that it was not finished with the issue: “Since it would be premature to change existing law on computer uses at present, the purpose of section 117 is to preserve the status quo.” In 1998, Congress amended Section 117 to permit copying software by turning on a computer if necessary to maintain or repair it, but we are still waiting for computer technology to “mature” enough for Congress to comprehensively update the “status quo.” While this is an extreme example, statutes in general tend to address what technology used to be. When technological progress is slow, statutes may continue to address what technology is. Statutes never address what technology will be in the future. When technological progress is rapid, literal application of statutes can lead to unintended — and sometimes absurd — results. For example, the Federal Communication Commission regulates over-the-air television transmissions but not broadcasting over the Internet. The challenge for the judiciary
The law is not powerless to adapt to changing technology during the gap between technological advance and legislative reaction — courts have the power to interpret statutes and can, in deciding specific cases, take into account legislative intent and how it might be applied to new technologies. The problem with case law is that it can be inconsistent and confusing. Congress can enact statutes regulating certain nationwide issues, but unless the subject is within its constitutional authority — and until Congress decides to act — each state has its own independent system of laws, determined by its legislature and its court system. Within each state and until an appellate court decides an issue, each trial judge is free to interpret the application of a statute to a new technology and to ignore the interpretations of other trial judges. Moreover, each state has its own judicial system with its own regime of judicial review, so courts in one state are not bound by the statutes or judicial decisions from other states. If there is federal jurisdiction, Congress can impose a uniform national solution; in the absence of federal jurisdiction, some degree of uniformity can be reached if state legislators adopt similar statutes. In the meantime, though, there is a real possibility of inconsistency, resulting confusion, and difficulty in planning. Because the Internet is not confined by state boundaries, anyone using the Internet is therefore exposed to the possibility of being subject to 50 different — and not necessarily compatible — rules. Some problems of law-lag
1. The law no longer means what it once meant. According to classical theory, there are two ways in which laws are created: legislative enactment and common-law judicial development. The general rule is that creation of new laws is committed to legislatures, and interpretation of existing laws is committed to the judiciary. These mechanisms for creating law involve explicit decisions by public officials; all are the result of a deliberative process informed by some degree of attention to public policy; and all are subject to established processes of review and, ultimately, accountability to the public. In a 2014 law review article, I pointed out a phenomenon that I referred to as “technological lawmaking.” One example I used was the advent of speed cameras. At the time that most speed laws were passed, getting a speeding ticket required meeting several conditions: exceeding the posted limit by enough to attract the attention of a police officer (which also meant speeding in the presence of a police officer), doing so for a long enough period of time for the police officer to establish evidence of speeding (prior to radar, this meant being followed by a police car long enough for the officer to match speed), and being pulled over and not having a good enough excuse to convince the officer not to issue a citation. Therefore, as a practical matter, a posted speed limit of 40 mph meant “40-ish,” with the likelihood of a ticket being small at 45 mph and increasingly likely with increasing speed. In effect, a 40-mph posted limit probably meant that the legislature wanted to keep speeds below 50 mph. Speed cameras, in effect, changed the meaning of “exceeding the speed limit” — speed could be monitored 24/7 and determined instantaneously and to an arbitrarily small amount over the posted limit. Yet few, if any, legislatures raised the posted limits to reflect this new reality. As a result, the meaning of “exceeding the speed limit” changed, not because a legislature changed it but because technology made it different. 2. Borders are no longer borders. Before the Internet, borders were physical and it was easy to know when you crossed one. A merchant who did not want to be subject to, say, California law could just stay out of (and not ship to) California. That is no longer possible. It is not even possible to be sure where a message or order is really coming from, so there is no sure way to avoid a specific jurisdiction. For a time, Congress provided some protection for merchants by prohibiting states from asserting sales-tax jurisdiction over Internet commerce, but that law has lapsed, and cash-hungry states have not missed the opportunity to increase revenues — and reporting requirements for merchants. 3. Human judgment has been devalued. Advances in artificial intelligence have produced dramatic results. But they have also produced errors that no human would have made. As companies and governments look for ways to cut costs and process more data, increased use of artificial intelligence poses challenges that no legislature is yet ready to resolve. 4. Technology is providing ways to avoid the literal wording of statutes faster than legislatures are updating the statutes. Unless legislatures are vigilant, the responsibility for deciding what the law is shifted away from elected officials, allowing the law to change without explicit notice to the public. This allows actions that are prohibited by law to suddenly lose their proscribed status simply because there is a new way to carry them out. Regulations of telegraph companies and fax machines just don’t seem very effective against spammers who use text messages and robocallers. The list is far from complete
We could add bigger issues, such as the consequences of technology companies that are so wealthy, with technology so embedded, that some can go toe to toe with many nations; or the emerging cooperation between some technology companies and some governments. But you get the idea. Next time, we’ll look at specific examples of some of the laws that have not kept pace with technological innovation — and the potential problems posed by this lag.
Max Stul Oppenheimer is a tenured full professor at the University of Baltimore School of Law, where he teaches business and intellectual property law. He is a registered patent attorney licensed to practice law in Maryland and D.C. Any opinions expressed in this article are his and are not intended as legal advice. You’re welcome to share! Do you know someone who would benefit from the information in this newsletter? Feel free to forward it to them. And encourage them to subscribe via our online signup form — it’s completely free!
Publisher: AskWoody Tech LLC (sb@askwoody.com); editor: Will Fastie (editor@askwoody.com). Trademarks: Microsoft and Windows are registered trademarks of Microsoft Corporation. AskWoody, Windows Secrets Newsletter, WindowsSecrets.com, WinFind, Windows Gizmos, Security Baseline, Perimeter Scan, Wacky Web Week, the Windows Secrets Logo Design (W, S or road, and Star), and the slogan Everything Microsoft Forgot to Mention all are trademarks and service marks of AskWoody Tech LLC. All other marks are the trademarks or service marks of their respective owners. Your subscription:
Copyright © 2021 AskWoody Tech LLC. All rights reserved. |




 The study used the setup shown at left (as illustrated in the white paper). For smartphone testing, the researchers used a Google Pixel 2 and an iPhone SE. The handsets connected via Wi-Fi to an Apple MacBook or a PC running Windows 10.
The study used the setup shown at left (as illustrated in the white paper). For smartphone testing, the researchers used a Google Pixel 2 and an iPhone SE. The handsets connected via Wi-Fi to an Apple MacBook or a PC running Windows 10.







Plus Membership
Donations from Plus members keep this site going. You can identify the people who support AskWoody by the Plus badge on their avatars.
AskWoody Plus members not only get access to all of the contents of this site -- including Susan Bradley's frequently updated Patch Watch listing -- they also receive weekly AskWoody Plus Newsletters (formerly Windows Secrets Newsletter) and AskWoody Plus Alerts, emails when there are important breaking developments.
Get Plus!
Recent Topics
-
KB5058379 / KB 5061768 Failures
by 26 seconds ago
-
Windows 10 23H2 Good to Update to ?
by 2 hours, 39 minutes ago
-
At last – installation of 24H2
by 3 hours, 23 minutes ago
-
MS-DEFCON 4: As good as it gets
by 1 minute ago
-
RyTuneX optimize Windows 10/11 tool
by 15 hours, 36 minutes ago
-
Can I just update from Win11 22H2 to 23H2?
by 8 hours, 55 minutes ago
-
Limited account permission error related to Windows Update
by 1 day, 4 hours ago
-
Another test post
by 1 day, 5 hours ago
-
Connect to someone else computer
by 23 hours, 35 minutes ago
-
Limit on User names?
by 1 day, 2 hours ago
-
Choose the right apps for traveling
by 16 hours, 35 minutes ago
-
BitLocker rears its head
by 36 minutes ago
-
Who are you? (2025 edition)
by 2 hours, 25 minutes ago
-
AskWoody at the computer museum, round two
by 18 hours, 58 minutes ago
-
A smarter, simpler Firefox address bar
by 1 day, 15 hours ago
-
Woody
by 2 days ago
-
24H2 has suppressed my favoured spider
by 13 minutes ago
-
GeForce RTX 5060 in certain motherboards could experience blank screens
by 2 days, 15 hours ago
-
MS Office 365 Home on MAC
by 2 days, 8 hours ago
-
Google’s Veo3 video generator. Before you ask: yes, everything is AI here
by 3 days, 5 hours ago
-
Flash Drive Eject Error for Still In Use
by 3 hours, 59 minutes ago
-
Windows 11 Insider Preview build 27863 released to Canary
by 4 days ago
-
Windows 11 Insider Preview build 26120.4161 (24H2) released to BETA
by 4 days ago
-
AI model turns to blackmail when engineers try to take it offline
by 3 days, 3 hours ago
-
Migrate off MS365 to Apple Products
by 3 days, 4 hours ago
-
Login screen icon
by 2 days, 18 hours ago
-
AI coming to everything
by 9 hours, 26 minutes ago
-
Mozilla : Pocket shuts down July 8, 2025, Fakespot shuts down on July 1, 2025
by 4 days, 15 hours ago
-
No Screen TurnOff???
by 4 days, 16 hours ago
-
Identify a dynamic range to then be used in another formula
by 4 days, 16 hours ago
Remembering Woody
